After a long pause, I come back with an interesting topic to share and experiment with. Right now we are re-architecture
Camunda 8. One important part (which I'm contributing to) is to get rid of Webapps Importer/Archivers and move
data aggregation closer to the engine (inside a Zeebe Exporter).
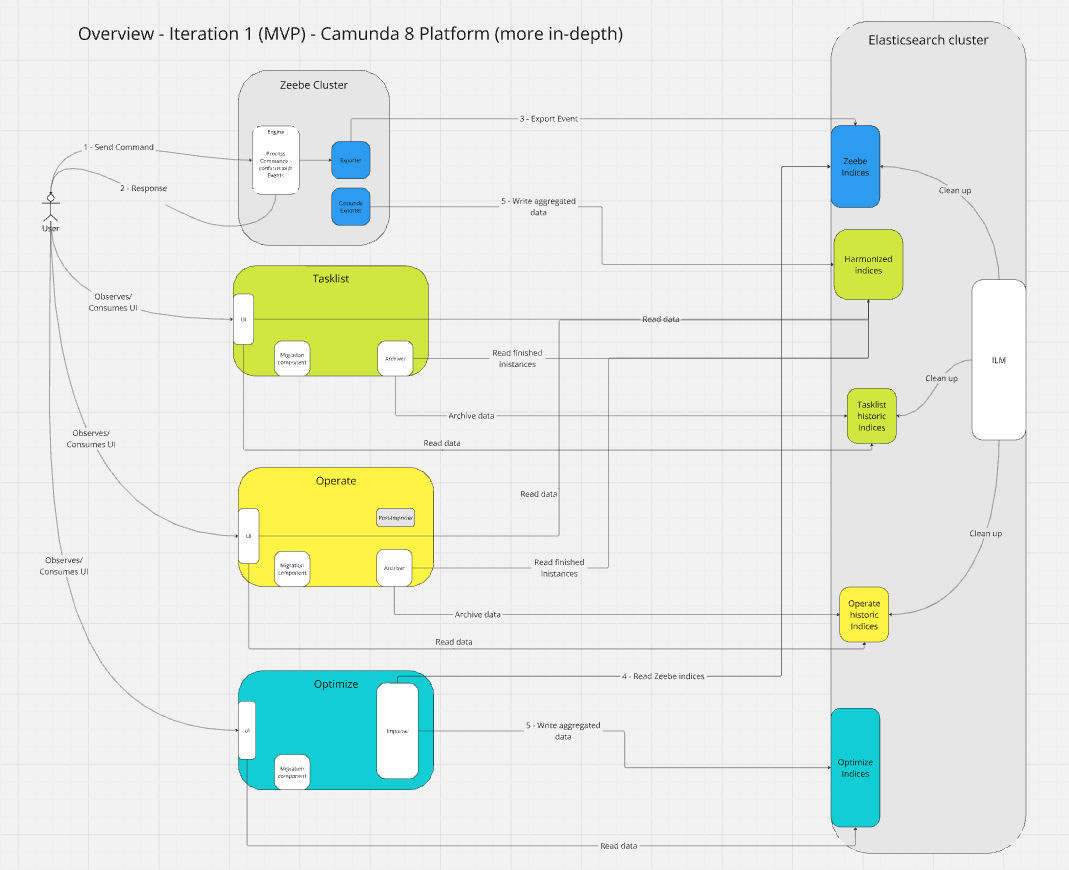
Today, I want to experiment with the first increment/iteration of our so-called MVP. The MVP targets green field installations where you simply deploy Camunda (with a new Camunda Exporter enabled) without Importers.
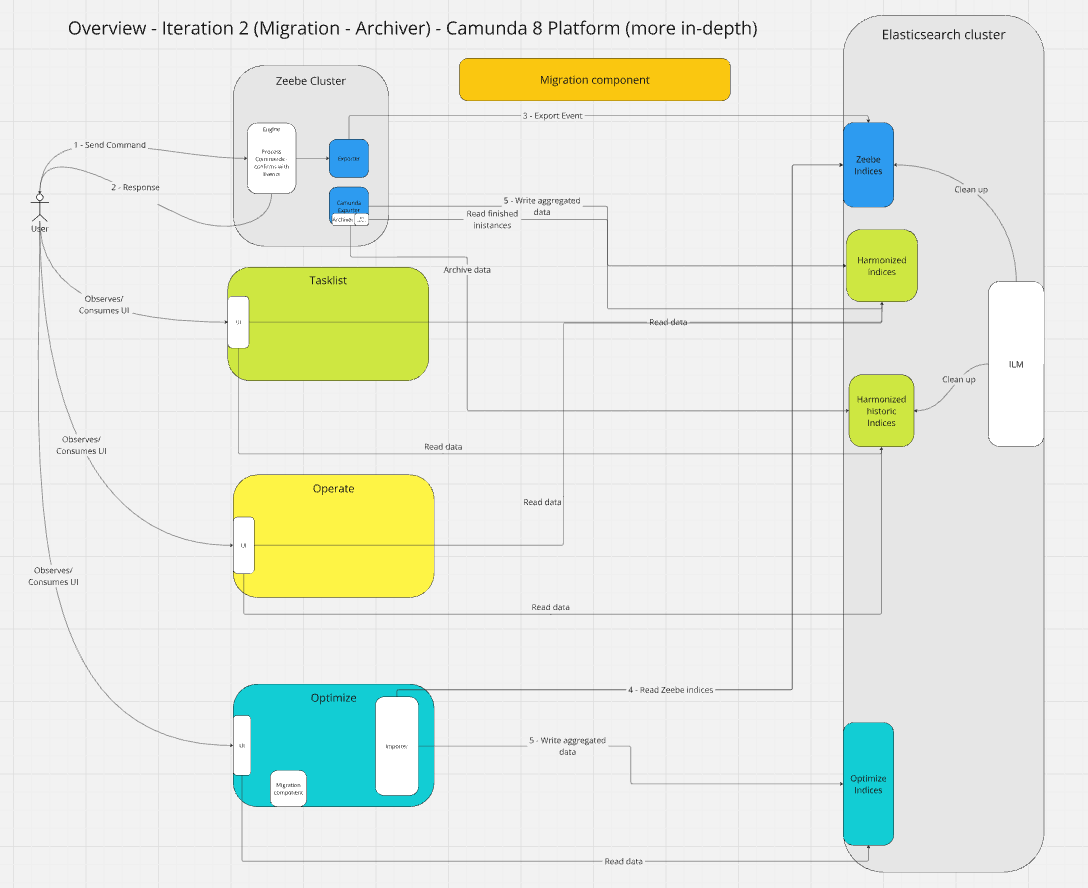
TL;DR; All our experiments were successful. The MVP is a success, and we are looking forward to further improvements and additions. Next stop Iteration 2: Adding Archiving historic data and preparing for data migration (and polishing MVP).
Camunda Exporter
The Camunda Exporter project deserves a complete own blog post, here is just a short summary.
Our current Camunda architecture looks something like this (simplified).
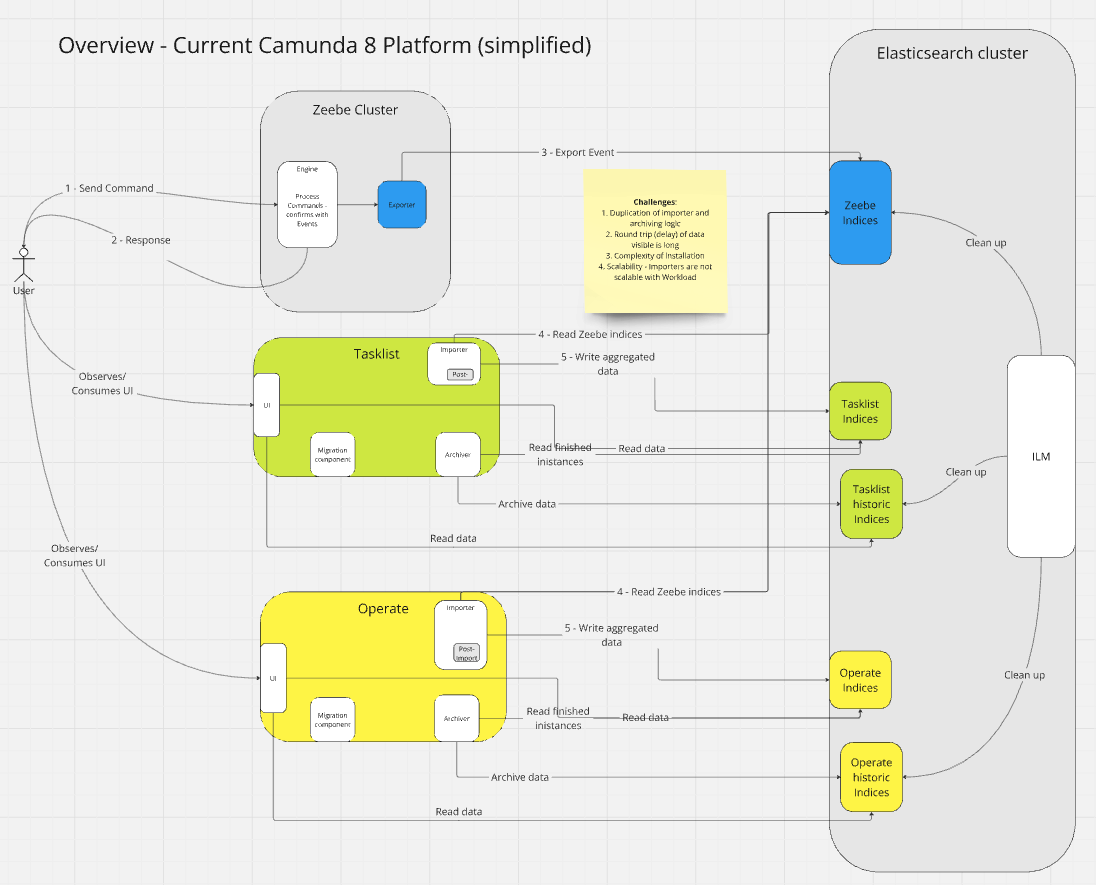
It has certain challenges, like:
- Space: duplication of data in ES
- Maintenance: duplication of importer and archiver logic
- Performance: Round trip (delay) of data visible to the user
- Complexity: installation and operational complexity (we need separate pods to deploy)
- Scalability: The Importer is not scalable in the same way as Zeebe or brokers (and workload) are.
These challenges we obviously wanted to overcome and the plan (as mentioned earlier) is to get rid of the need of separate importers and archivers (and in general to have separate application; but this is a different topic).
The plan for this project looks something like this:
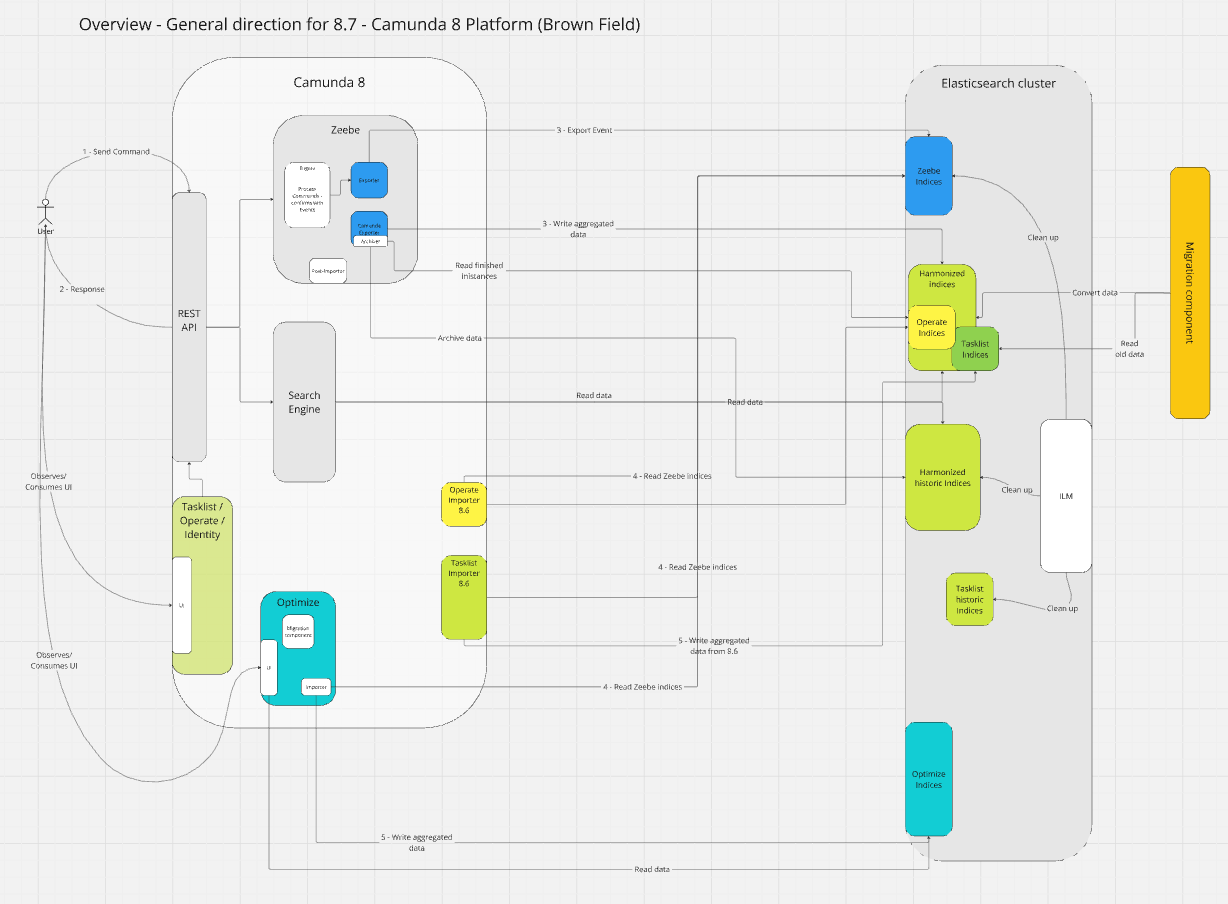
We plan to:
- Harmonize the existing indices stored in Elasticsearch/Opensearch
- Space: Reduce the unnecessary data duplication
- Move importer and archiver logic into a new Camunda exporter
- Performance: This should allow us to reduce one additional hop (as we don't need to use ES/OS as a queue)
- Maintenance: Indices and business logic is maintained in one place
- Scalability: With this approach, we can scale with partitions, as Camunda Exporters are executed for each partition separately (soon partition scaling will be introduced)
- Complexity: The Camunda Exporter will be built-in and shipped with Zeebe/Camunda 8. No additional pod/application is needed.
Note: Optimize is right now out of scope (due to time), but will later be part of this as well.
MVP
After we know what we want to achieve what is the Minimum viable product (MVP)?
We have divided the Camunda Exporter in 3-4 iterations. You can see and read more about this here.
The first iteration contains the MVP (the first breakthrough). Providing the Camunda Exporter with the basic functionality ported from the Operate and Tasklist importers, writing into harmonized indices.
The MVP is targeting green field installations (clean installations) of Camunda 8 with Camunda Exporter without running the old Importer (no data migration yet),