Bring Deployment distribution experiment back

We encountered recently a severe bug zeebe#9877 and I was wondering why we haven't spotted it earlier, since we have chaos experiments for it. I realized two things:
- The experiments only check for parts of it (BPMN resource only). The production code has changed, and a new feature has been added (DMN) but the experiments/tests haven't been adjusted.
- More importantly we disabled the automated execution of the deployment distribution experiment because it was flaky due to a missing standalone gateway in Camunda Cloud SaaS zeebe-io/zeebe-chaos#61. This is no longer the case, see Standalone Gateway in CCSaaS
On this chaos day I want to bring the automation of this chaos experiment back to life. If I have still time I want to enhance the experiment.
TL;DR; The experiment still worked, and our deployment distribution is still resilient against network partitions. It also works with DMN resources. I can enable the experiment again, and we can close zeebe-io/zeebe-chaos#61. Unfortunately, we were not able to reproduce zeebe#9877 but we did some good preparation work for it.
Chaos Experiment
To recap, when a deployment is created by a client it is sent to the partition one leader. Partition one is in charge of distributing the deployment to the other partitions. That means it will send the deployment to the other partition leaders, this is retried as long no ACK was received from the corresponding partition leader.
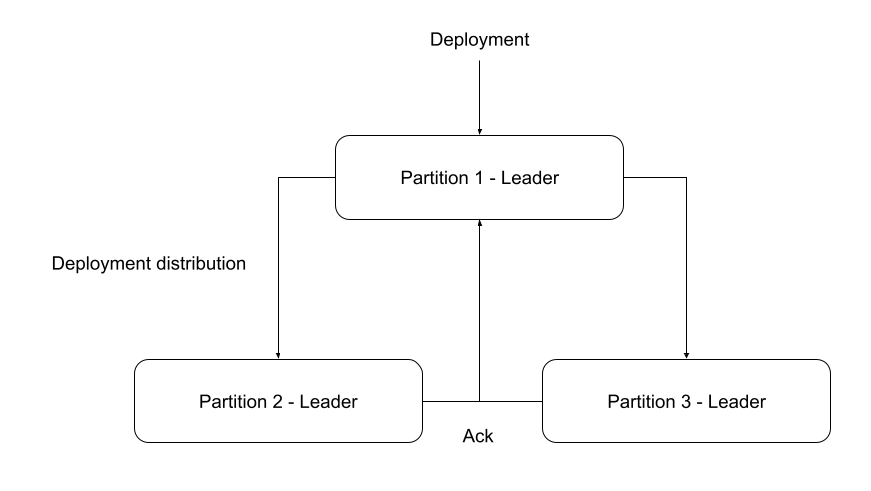
We already have covered that in more detail in another chaos day you can read here.
Expected

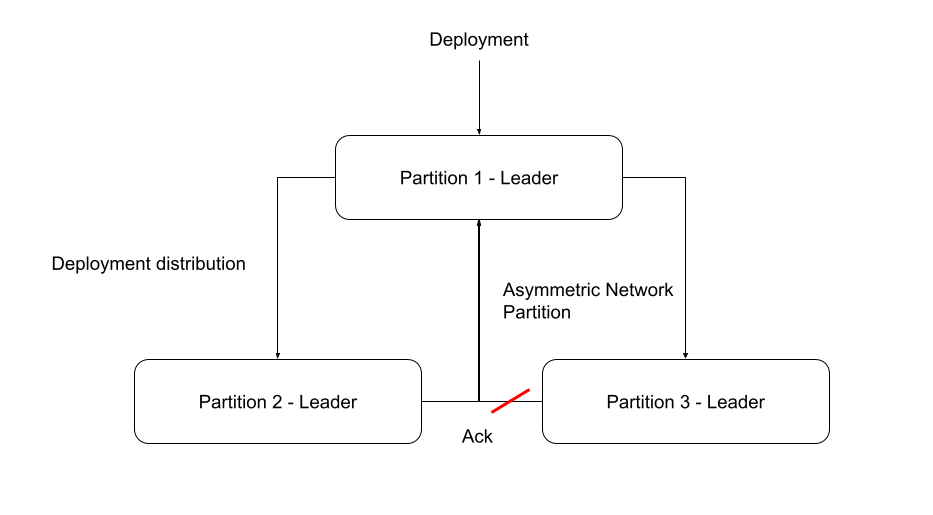
As you can see in the image we will create an asymmetric network partition and disconnect the partition one leader from partition three. That means the sending to partition three will not be possible. We use here an asymmetric network partition, in order to reduce the probability to cause a leader change. The partition one leader is a follower of partition three and will still receive heartbeats.
After disconnecting the leaders we deploy multiple process versions and after connecting the leaders again we expect that the deployments are distributed. It is expected that we can create instances of the last version on all partitions.
We will run the existing experiment against the latest minor version, to verify whether the experiment still works. When we enable the experiment again for automation it will be executed against SNAPSHOT automatically.
Actual
Setup
As a first step, we created a new Production-S cluster, which has three partitions, three nodes (brokers), and two standalone gateways. The Zeebe version was set to 8.0.4 (latest minor).
It was a while since I used the chaostoolkit which is the reason I had to reinstall it again, which is quite a simple see here.
TL;DR:
python3 -m venv ~/.venvs/chaostk
source ~/.venvs/chaostk/bin/activate
pip install -U chaostoolkit
chaos --version
Executing chaos toolkit
As mentioned, the deployment distribution was not enabled for Production-S clusters, which is currently the only configuration we test via Zeebe Testbench. We have to use the experiment that is defined under production-l/deployment-distribution, which is the same*.
* That is not 100% true. During running the Production-l experiment I realized that it made some assumptions regarding the partition count which needs to be adjusted for the Production-S setup. chaos run production-l/deployment-distribution/experiment.json
[2022-08-02 09:35:25 INFO] Validating the experiment's syntax
[2022-08-02 09:35:25 INFO] Experiment looks valid
[2022-08-02 09:35:25 INFO] Running experiment: Zeebe deployment distribution
[2022-08-02 09:35:25 INFO] Steady-state strategy: default
[2022-08-02 09:35:25 INFO] Rollbacks strategy: default
[2022-08-02 09:35:25 INFO] Steady state hypothesis: Zeebe is alive
[2022-08-02 09:35:25 INFO] Probe: All pods should be ready
[2022-08-02 09:35:25 INFO] Steady state hypothesis is met!
[2022-08-02 09:35:25 INFO] Playing your experiment's method now...
[2022-08-02 09:35:25 INFO] Action: Enable net_admin capabilities
[2022-08-02 09:35:26 WARNING] This process returned a non-zero exit code. This may indicate some error and not what you expected. Please have a look at the logs.
[2022-08-02 09:35:26 INFO] Pausing after activity for 180s...
[2022-08-02 09:38:26 INFO] Probe: All pods should be ready
[2022-08-02 09:38:33 INFO] Action: Create network partition between leaders
[2022-08-02 09:38:34 WARNING] This process returned a non-zero exit code. This may indicate some error and not what you expected. Please have a look at the logs.
[2022-08-02 09:38:34 INFO] Action: Deploy different deployment versions.
[2022-08-02 09:38:40 INFO] Action: Delete network partition
[2022-08-02 09:38:42 INFO] Probe: Create process instance of latest version on partition one
[2022-08-02 09:38:43 INFO] Probe: Create process instance of latest version on partition two
[2022-08-02 09:38:44 INFO] Probe: Create process instance of latest version on partition three
[2022-08-02 09:38:44 INFO] Steady state hypothesis: Zeebe is alive
[2022-08-02 09:38:44 INFO] Probe: All pods should be ready
[2022-08-02 09:38:45 INFO] Steady state hypothesis is met!
[2022-08-02 09:38:45 INFO] Let's rollback...
[2022-08-02 09:38:45 INFO] No declared rollbacks, let's move on.
[2022-08-02 09:38:45 INFO] Experiment ended with status: completed
Based on the tool output it looks like it succeed, to make sure it really worked, we will take a look at the logs in stackdriver.
In the following logs we can see that deployment distribution is failing for partition 3 and is retried, which is expected and what we wanted.
2022-08-02 09:38:53.114 CEST zeebe Failed to receive deployment response for partition 3 (on topic 'deployment-response-2251799813685347-3'). Retrying
2022-08-02 09:38:53.115 CEST zeebe Deployment DISTRIBUTE command for deployment 2251799813685347 was written on partition 3
2022-08-02 09:38:53.157 CEST zeebe Received new exporter state {elasticsearch=228, MetricsExporter=228}
2022-08-02 09:38:53.157 CEST zeebe Received new exporter state {elasticsearch=228, MetricsExporter=228}
2022-08-02 09:38:53.241 CEST zeebe Received new exporter state {elasticsearch=232, MetricsExporter=232}
2022-08-02 09:38:53.241 CEST zeebe Received new exporter state {elasticsearch=232, MetricsExporter=232}
2022-08-02 09:38:53.464 CEST zeebe Failed to receive deployment response for partition 3 (on topic 'deployment-response-2251799813685351-3'). Retrying
2022-08-02 09:38:53.466 CEST zeebe Deployment DISTRIBUTE command for deployment 2251799813685351 was written on partition 3
2022-08-02 09:38:54.216 CEST zeebe Failed to receive deployment response for partition 3 (on topic 'deployment-response-2251799813685353-3'). Retrying
2022-08-02 09:38:54.218 CEST zeebe Deployment DISTRIBUTE command for deployment 2251799813685353 was written on partition 3
2022-08-02 09:38:54.224 CEST zeebe Failed to receive deployment response for partition 3 (on topic 'deployment-response-2251799813685355-3'). Retrying
2022-08-02 09:38:54.225 CEST zeebe Deployment DISTRIBUTE command for deployment 2251799813685355 was written on partition 3
2022-08-02 09:38:55.055 CEST zeebe Failed to receive deployment response for partition 3 (on topic 'deployment-response-2251799813685359-3'). Retrying
2022-08-02 09:38:55.057 CEST zeebe Deployment DISTRIBUTE command for deployment 2251799813685359 was written on partition 3
2022-08-02 09:38:55.689 CEST zeebe Received new exporter state {elasticsearch=299, MetricsExporter=299}
2022-08-02 09:38:55.690 CEST zeebe Received new exporter state {elasticsearch=299, MetricsExporter=299}
2022-08-02 09:38:56.089 CEST zeebe Failed to receive deployment response for partition 3 (on topic 'deployment-response-2251799813685357-3'). Retrying
2022-08-02 09:38:56.090 CEST zeebe Deployment DISTRIBUTE command for deployment 2251799813685357 was written on partition 3
2022-08-02 09:38:56.272 CEST zeebe Failed to receive deployment response for partition 3 (on topic 'deployment-response-2251799813685363-3'). Retrying
2022-08-02 09:38:56.273 CEST zeebe Deployment DISTRIBUTE command for deployment 2251799813685363 was written on partition 3
2022-08-02 09:38:56.920 CEST zeebe Failed to receive deployment response for partition 3 (on topic 'deployment-response-2251799813685361-3'). Retrying
2022-08-02 09:38:56.922 CEST zeebe Deployment DISTRIBUTE command for deployment 2251799813685361 was written on partition 3
2022-08-02 09:39:08.369 CEST zeebe Received new exporter state {elasticsearch=252, MetricsExporter=252}
At some point, the retry stopped, and we can see in the experiment output that we were able to start process instances on all partitions. This is great because it means the experiment was successfully executed and our deployment distribution is failure tolerant.
Enhancement
As described earlier the current experiment deploys a BPMN process model only. It looks like this:
In order to make DMN part of the experiment, we change the service task to a Business Rule task.
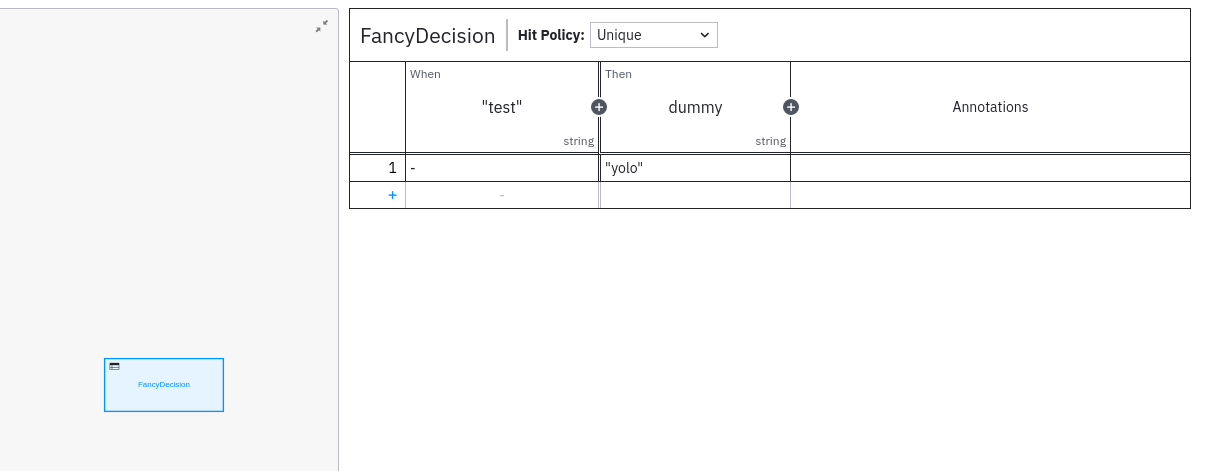
The decision is really simple and just defines a static input and returns that as output.
When we run our experiment and create process instances on all partitions the DMN needs to be available otherwise the execution would fail. Currently, we can't specify a specific version of the DMN in the Business Rule Task (always the latest will be executed). Because of that, we will not deploy different DMN model versions, since it is currently not that easy to verify whether the right version was chosen.
After adjusting the model and adjusting the script, we run the experiment again.
$ chaos run production-l/deployment-distribution/experiment.json
[2022-08-02 11:05:12 INFO] Validating the experiment's syntax
[2022-08-02 11:05:12 INFO] Experiment looks valid
[2022-08-02 11:05:12 INFO] Running experiment: Zeebe deployment distribution
[2022-08-02 11:05:12 INFO] Steady-state strategy: default
[2022-08-02 11:05:12 INFO] Rollbacks strategy: default
[2022-08-02 11:05:12 INFO] Steady state hypothesis: Zeebe is alive
[2022-08-02 11:05:12 INFO] Probe: All pods should be ready
[2022-08-02 11:05:13 INFO] Steady state hypothesis is met!
[2022-08-02 11:05:13 INFO] Playing your experiment's method now...
[2022-08-02 11:05:13 INFO] Action: Enable net_admin capabilities
[2022-08-02 11:05:13 WARNING] This process returned a non-zero exit code. This may indicate some error and not what you expected. Please have a look at the logs.
[2022-08-02 11:05:13 INFO] Pausing after activity for 180s...
[2022-08-02 11:08:14 INFO] Probe: All pods should be ready
[2022-08-02 11:08:14 INFO] Action: Create network partition between leaders
[2022-08-02 11:08:16 WARNING] This process returned a non-zero exit code. This may indicate some error and not what you expected. Please have a look at the logs.
[2022-08-02 11:08:16 INFO] Action: Deploy different deployment versions.
[2022-08-02 11:08:25 INFO] Action: Delete network partition
[2022-08-02 11:08:27 INFO] Probe: Create process instance of latest version on partition one
[2022-08-02 11:08:27 INFO] Probe: Create process instance of latest version on partition two
[2022-08-02 11:08:28 INFO] Probe: Create process instance of latest version on partition three
[2022-08-02 11:08:29 INFO] Steady state hypothesis: Zeebe is alive
[2022-08-02 11:08:29 INFO] Probe: All pods should be ready
[2022-08-02 11:08:29 INFO] Steady state hypothesis is met!
[2022-08-02 11:08:29 INFO] Let's rollback...
[2022-08-02 11:08:29 INFO] No declared rollbacks, let's move on.
[2022-08-02 11:08:29 INFO] Experiment ended with status: completed
It succeeded as well.
Taking a look at Operate we can see some incidents.

It seems the process instance execution runs into the Business Rule Task, but the DMN resource was not available on the partition.
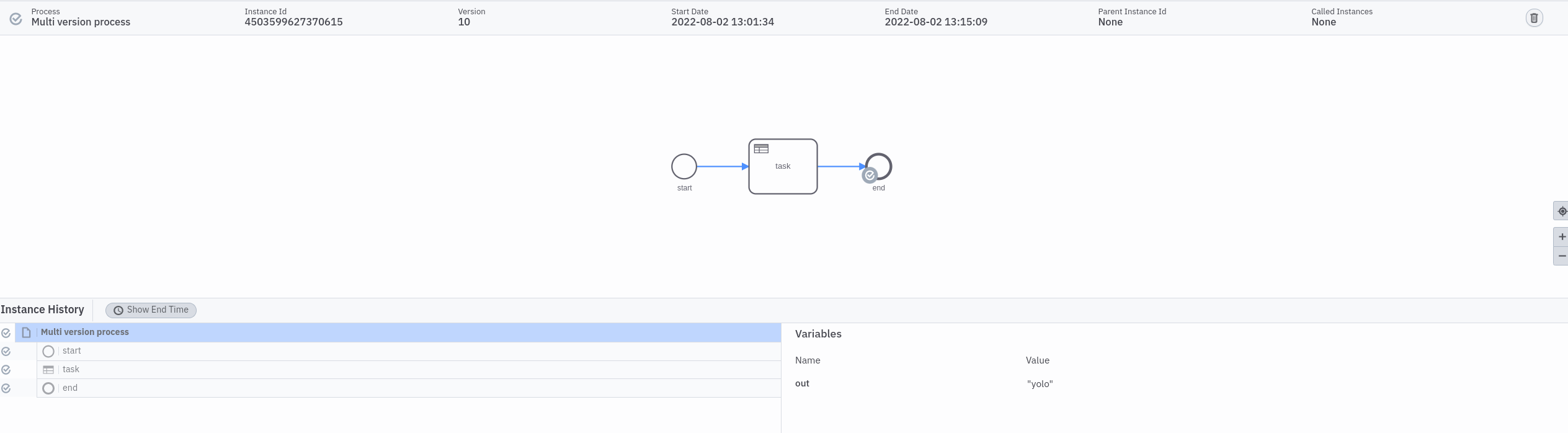
After retrying in Operate the incident was resolved, which means the DMN resource was distributed at that time.
We can adjust the experiment further to await the result of the process execution, but I will stop here and leave that for a later point.
Reproduce our bug
The current experiment didn't reproduce the bug in zeebe#9877, since the DMN resource has to be distributed multiple times. Currently, we create a network partition such that the distribution doesn't work at all.
In order to reproduce our scenario, we can set the network partition in the other direction, such that the acknowledgment is not received by the leader one.
Adjusting the experiment (script) like this:
-retryUntilSuccess disconnect "$leader" "$leaderTwoIp"
+retryUntilSuccess disconnect "$leaderTwo" "$leaderIp"
Should do the trick, but I was not yet able to reproduce the issue with 8.0.4. It seems we need to spend some more time reproducing the bug. But I think with today's changes we already did a good step in the right direction, and we can improve based on that. I will create a follow-up issue to improve our experiment.
Further Work
Based on today's outcome we can enable again the Deployment Distribution experiment for Production-S, such that is executed by Zeebe Testbench (our automation tooling). We can close zeebe-io/zeebe-chaos#61
We should adjust our Chaos Worker implementation such that we also deploy DMN resources as we did in today's Chaos Day, since the scripts we changed aren't used in the automation.
I will create a follow-up issue to improve our experiment, so we can reproduce the critical bug.
Found Bugs
none