High CPU load on Standalone Gateway

- Updated failure cases documentation for exporter based on review
- Documented failure cases for ZeebeDB
- Wrote an chaostoolkit experiment based on the last manual Chaos experiment
- Run a chaos experiment with @Deepthi, where we put high CPU load on the standalone gateway https://github.com/zeebe-io/zeebe-chaos/issues/28
Chaos experiment:
We did today an chaos experiment where we used our standard setup with a baseline load of 100 workflow instance and 6 workers, which can activate 120 jobs max. On our steady state we saw that we are able to start and complete 100 workflow instances in a second. One instance took 1 - 2.5 seconds.
We expected when we introduce stress on the standalone gateway CPU that the latency of the processing goes up and the throughput goes down, but there should be no cluster wide failures happening. We expected that after removing the stress the system should come back to normal and the baseline should be reached again.
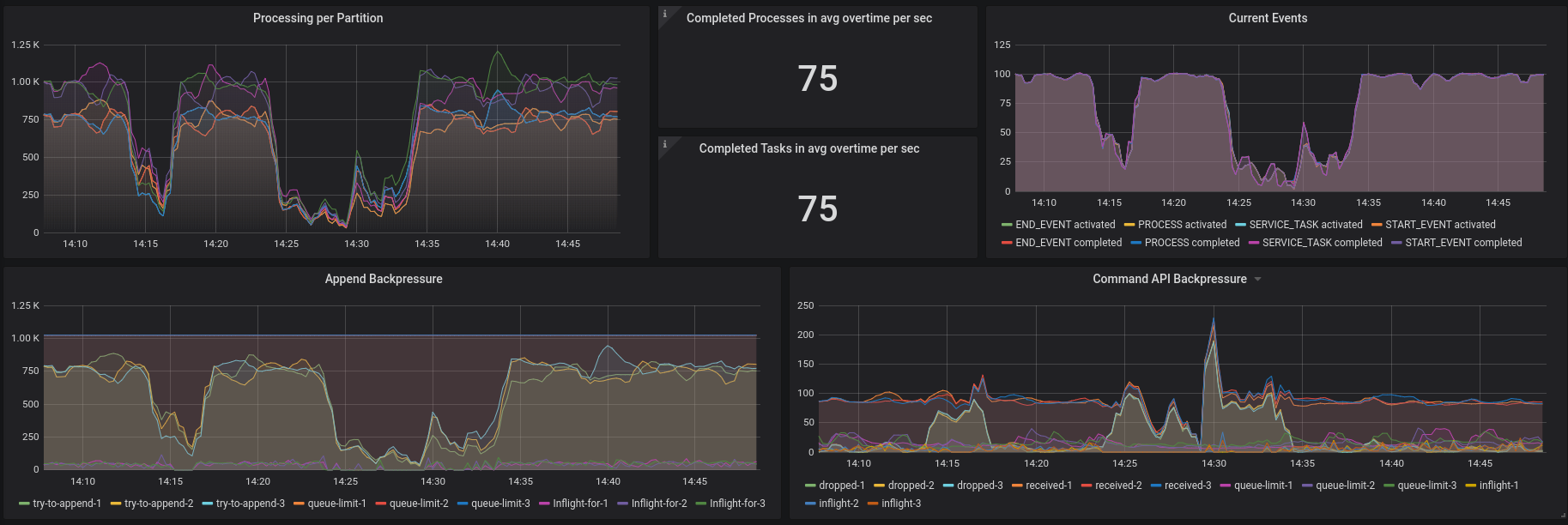
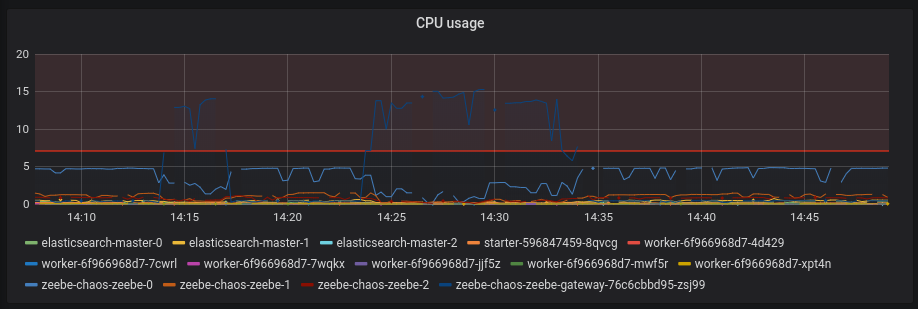
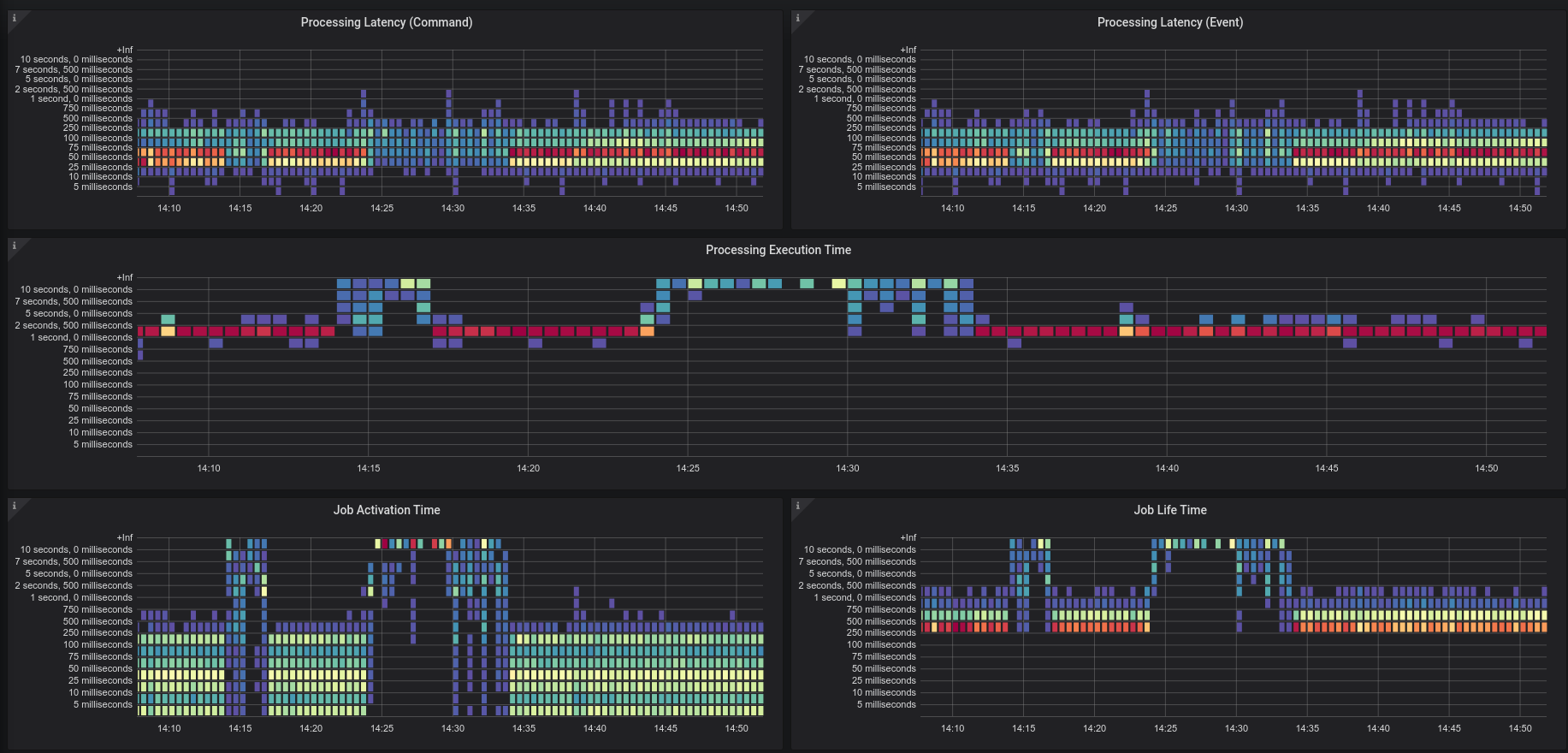
The results look promising. We have seen no outage. We tested it twice and saw that the throughput goes down and latency up on stress, but comes back to normal after removing it.
What was unexpected or what we found out:
Unexpected was that our Broker back pressure goes up, which means it drops requests during the stress time. This was not expected, since the latency between writing to dispatcher and processing the event should not change. We probably need to investigate this more. Current assumption is that the gateway sends requests in batches and this causes in higher spikes on the back pressure. We need more metrics on the transport module to verify that. There is already an open issue for that https://github.com/zeebe-io/zeebe/issues/4487 We might need to tackle this, before we can find out more here.
We found out that the standalone gateway is not resource limited, which caused that we used at some point 12 CPU cores. It seems there is also an open issue for that on the helm charts https://github.com/zeebe-io/zeebe-cluster-helm/issues/74
We want to improve on our current chaos toolkit test. We want to introduce failures and verify the steady state during the failure is happening, on rollback we should remove the failure again. We currently just verify that we can recover, but not the behavior during a failure, which might be also interesting.
Participants
- @deepthidevaki
- @zelldon